Journals > > Topics > Image Processing
Image Processing|1225 Article(s)
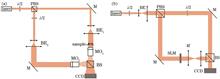
End-to-End Phase Reconstruction of Digital Holography Based on Improved Residual Unet
Kunge Li, Huaying Wang, Xu Liu, Jieyu Wang, Wenjian Wang, and Liu Yang
Digital holography (DH) is critical for monitoring quantitative three-dimensional information of transparent samples. However, phase aberration compensation and unwrapping are needed in conventional digital holographic reconstruction, which adversely affect its speed and accuracy. We propose an improved residual Unet method that combines dilated convolution and attention mechanism to implement end-to-end phase reconstruction of DH, which simplifies the imaging process and improves the quality of image reconstruction. In addition, the proposed method can further optimize the network model for real-time reconstruction by adjusting residual blocks. The experimental results reveal that the proposed phase reconstruction method based on deep learning can obtain accurate three-dimensional information of samples in real time, which benefits real-time monitoring for dynamic samples. Digital holography (DH) is critical for monitoring quantitative three-dimensional information of transparent samples. However, phase aberration compensation and unwrapping are needed in conventional digital holographic reconstruction, which adversely affect its speed and accuracy. We propose an improved residual Unet method that combines dilated convolution and attention mechanism to implement end-to-end phase reconstruction of DH, which simplifies the imaging process and improves the quality of image reconstruction. In addition, the proposed method can further optimize the network model for real-time reconstruction by adjusting residual blocks. The experimental results reveal that the proposed phase reconstruction method based on deep learning can obtain accurate three-dimensional information of samples in real time, which benefits real-time monitoring for dynamic samples.
Laser & Optoelectronics Progress
- Publication Date: Mar. 25, 2023
- Vol. 60, Issue 6, 0610016 (2023)

Design of Shoe Print Feature Extraction Network Integrating Global and Local Features
Yiran Xin, Yunqi Tang, and Nengbin Cai
A feature extraction network using global and local features is designed to tackle the issue of retrieving incomplete and fuzzy shoe prints. The global features of the multiscale shoe print are normalized and weighted, and the losses of all their outputs are calculated; moreover, the part-based Conv baseline (PCB) module is used to divide the shoe print feature map into three parts, extract the local features of the three parts, and calculate their losses. During the training phase, all of the global feature branch and local feature branch losses are added to express them collectively. The output of the two branches after splicing is directly flattened as the shoe print descriptor to be retrieved in the test phase, and the cosine distance between it and the descriptor of the sample library shoe print is used as the similarity score. The experimental results show that the proposed method significantly reduces the parameter quantity and calculation cost of the model, and achieves high accuracy on the three shoe print data sets of CSS-200, CS Database, and FID-300. Furthermore, it achieves decent accuracy on the top1% of the CSS-200 and CS Database (Dust) datasets, which are 94.5% and 95.45%, respectively. A feature extraction network using global and local features is designed to tackle the issue of retrieving incomplete and fuzzy shoe prints. The global features of the multiscale shoe print are normalized and weighted, and the losses of all their outputs are calculated; moreover, the part-based Conv baseline (PCB) module is used to divide the shoe print feature map into three parts, extract the local features of the three parts, and calculate their losses. During the training phase, all of the global feature branch and local feature branch losses are added to express them collectively. The output of the two branches after splicing is directly flattened as the shoe print descriptor to be retrieved in the test phase, and the cosine distance between it and the descriptor of the sample library shoe print is used as the similarity score. The experimental results show that the proposed method significantly reduces the parameter quantity and calculation cost of the model, and achieves high accuracy on the three shoe print data sets of CSS-200, CS Database, and FID-300. Furthermore, it achieves decent accuracy on the top1% of the CSS-200 and CS Database (Dust) datasets, which are 94.5% and 95.45%, respectively.
Laser & Optoelectronics Progress
- Publication Date: Mar. 25, 2023
- Vol. 60, Issue 6, 0610015 (2023)
Multitarget Real-Time Tracking Algorithm Based on Transformer and BYTE Data
Hao Pan, Xiang Liu, Jingwen Zhao, and Xing Zhang
To solve the problems of trajectory missed detection, misdetection, and identity switching in complex multitarget tracking, this paper proposes a multitarget tracking algorithm based on improved YOLOX and BYTE data association methods. First, to enhance YOLOX's target detection capabilities in complex environments, we combine the YOLOX backbone network and Vision Transformer to improve the network's local feature extraction capability and add the α-GIoU loss function to further improve the regression accuracy of the network bounding box. Second, to meet the real-time requirements of the algorithm, we employ the BYTE data association method, abandon the traditional feature rerecognition (Re-ID) network, and further improving the speed of the proposed multitarget tracking algorithm. Finally, to mitigate the tracking problems in complex environments, such as illumination and occlusion, we adopt the extended Kalman filter, which is more adaptive to the nonlinear system, to improve the prediction accuracy of the network for tracking trajectory in complex scenes. The experimental results show that the multiple object tracking accuracy (MOTA) and identity F1-measure (IDF1) of the proposed algorithm on the MOT17 dataset are 73.0% and 70.2%, respectively, compared with the current optimal algorithm ByteTrack, they are improved by 1.3 percentage points and 2.1 percentage points, respectively, whereas number of identity switches (IDSW) is reduced by 3.7%. Meanwhile, the proposed algorithm achieves a tracking speed of 51.2 frames/s, which meets the real-time requirements of the system. To solve the problems of trajectory missed detection, misdetection, and identity switching in complex multitarget tracking, this paper proposes a multitarget tracking algorithm based on improved YOLOX and BYTE data association methods. First, to enhance YOLOX's target detection capabilities in complex environments, we combine the YOLOX backbone network and Vision Transformer to improve the network's local feature extraction capability and add the α-GIoU loss function to further improve the regression accuracy of the network bounding box. Second, to meet the real-time requirements of the algorithm, we employ the BYTE data association method, abandon the traditional feature rerecognition (Re-ID) network, and further improving the speed of the proposed multitarget tracking algorithm. Finally, to mitigate the tracking problems in complex environments, such as illumination and occlusion, we adopt the extended Kalman filter, which is more adaptive to the nonlinear system, to improve the prediction accuracy of the network for tracking trajectory in complex scenes. The experimental results show that the multiple object tracking accuracy (MOTA) and identity F1-measure (IDF1) of the proposed algorithm on the MOT17 dataset are 73.0% and 70.2%, respectively, compared with the current optimal algorithm ByteTrack, they are improved by 1.3 percentage points and 2.1 percentage points, respectively, whereas number of identity switches (IDSW) is reduced by 3.7%. Meanwhile, the proposed algorithm achieves a tracking speed of 51.2 frames/s, which meets the real-time requirements of the system.
Laser & Optoelectronics Progress
- Publication Date: Mar. 25, 2023
- Vol. 60, Issue 6, 0610014 (2023)
Pedestrian Target Detection in Subway Scene Using Improved YOLOv5s Algorithm
Xiuzai Zhang, Ye Qiu, and Chen Zhang
Pedestrian targets in subway scenes pose problems such as varying sizes, different degrees of occlusion, and blurred images caused by dark environments, which adversely affect the accuracy of pedestrian target detection. To address these problems, this study proposes an improved YOLOv5s target detection algorithm to improve the accuracy of pedestrian target detection in subway scene video signals. The pedestrian dataset of a subway scene is constructed, the corresponding labels are marked, and the data preprocessing operation is performed. Moreover, a deep residual shrinkage network is added to the feature extraction module, and the residual network, attention mechanism, and soft thresholding function are combined to enhance the useful feature channel and weaken the redundant feature channel. The fusion features of multiscale and multireceptive fields of the image are obtained using the improved atrous spatial pyramid pooling module without losing image information, and the global context information of the image is effectively captured. The improved non-maximum suppression algorithm is designed to postprocess the target prediction frame and retain the optimal prediction frame of the detection target. The experimental results demonstrate that the improved YOLOv5s algorithm proposed in this study can effectively improve the accuracy of pedestrian target detection in subway scene video signals, particularly for small and dense pedestrian target scenes. Pedestrian targets in subway scenes pose problems such as varying sizes, different degrees of occlusion, and blurred images caused by dark environments, which adversely affect the accuracy of pedestrian target detection. To address these problems, this study proposes an improved YOLOv5s target detection algorithm to improve the accuracy of pedestrian target detection in subway scene video signals. The pedestrian dataset of a subway scene is constructed, the corresponding labels are marked, and the data preprocessing operation is performed. Moreover, a deep residual shrinkage network is added to the feature extraction module, and the residual network, attention mechanism, and soft thresholding function are combined to enhance the useful feature channel and weaken the redundant feature channel. The fusion features of multiscale and multireceptive fields of the image are obtained using the improved atrous spatial pyramid pooling module without losing image information, and the global context information of the image is effectively captured. The improved non-maximum suppression algorithm is designed to postprocess the target prediction frame and retain the optimal prediction frame of the detection target. The experimental results demonstrate that the improved YOLOv5s algorithm proposed in this study can effectively improve the accuracy of pedestrian target detection in subway scene video signals, particularly for small and dense pedestrian target scenes.
Laser & Optoelectronics Progress
- Publication Date: Mar. 25, 2023
- Vol. 60, Issue 6, 0610013 (2023)
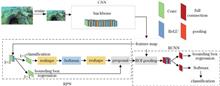
Underwater Target Detection Algorithm Based on Automatic Color Level and Bidirectional Feature Fusion
Ting Yang, Wuqi Gao, Peng Wang, Xiaoyan Li, Lü Zhigang, and Ruohai Di
Many complex elements such as poor light and high noise in the underwater environment result in low detection accuracy and high missed detection rate in traditional underwater target detection methods. To address these issues, based on the current general Faster R-CNN algorithm, this study proposes an underwater target detection algorithm based on automatic color level and bidirectional feature fusion. First, the automatic color level was used to enhance a blurred underwater image. Second, the path aggregation feature pyramid network (PAFPN) was introduced for feature fusion to enhance the expression for shallow information. Third, the soft non-maximum suppression (Soft-NMS) algorithm was introduced to modify and generate the candidate target regions before and after training. Finally, the FocalLoss function was used to rectify the issue of an unbalanced distribution of positive and negative samples. The experimental results show that the proposed algorithm can reach a detection accuracy of 59.7% on the URPC2020 dataset and a recall rate of 70.5%, which are 5.5 percentage points and 8.4 percentage points respectively higher than the current general Faster R-CNN algorithm, effectively improving the average accuracy of underwater target detection. Many complex elements such as poor light and high noise in the underwater environment result in low detection accuracy and high missed detection rate in traditional underwater target detection methods. To address these issues, based on the current general Faster R-CNN algorithm, this study proposes an underwater target detection algorithm based on automatic color level and bidirectional feature fusion. First, the automatic color level was used to enhance a blurred underwater image. Second, the path aggregation feature pyramid network (PAFPN) was introduced for feature fusion to enhance the expression for shallow information. Third, the soft non-maximum suppression (Soft-NMS) algorithm was introduced to modify and generate the candidate target regions before and after training. Finally, the FocalLoss function was used to rectify the issue of an unbalanced distribution of positive and negative samples. The experimental results show that the proposed algorithm can reach a detection accuracy of 59.7% on the URPC2020 dataset and a recall rate of 70.5%, which are 5.5 percentage points and 8.4 percentage points respectively higher than the current general Faster R-CNN algorithm, effectively improving the average accuracy of underwater target detection.
Laser & Optoelectronics Progress
- Publication Date: Mar. 25, 2023
- Vol. 60, Issue 6, 0610012 (2023)

Multiscale Dense Attention Network for Retinal Vessel Segmentation
Liming Liang, Jie Yu, Longsong Zhou, Xin Chen, and Jian Wu
The problem of retinal blood vessel segmentation, such as limited labeled image data, complex blood vessel structure with different scales, and easy to be disturbed by the lesion area, is a concern for researchers. Thus, to address this problem, the study proposes a multiscale dense attention network for retinal blood vessel segmentation. First, based on U-Net architecture, the concurrent spatial and channel squeeze and channel excitation attention dense block (scSE-DB) is used to replace the traditional convolution layer, strengthening the feature propagation ability, and obtaining a dual calibration for feature information so that the model can better identify blood vessel pixels. Second, a cascade hole convolution module is embedded at the bottom of the network to capture multiscale vascular feature information and improve the network's ability to obtain deep semantic features. Finally, we performed the experiments on three datasets (DRIVE dataset, CHASE_DB1 dataset, and STARE dataset), and the results show that the accuracy of the proposed network is 96.50%, 96.62%, and 96.75%; the sensitivity is 84.17%, 83.34%, and 80.39%, and the specificity is 98.22%, 97.95%, and 98.67%, respectively. Generally, the results show that the segmentation performance of the proposed network outperforms that of other advanced algorithms. The problem of retinal blood vessel segmentation, such as limited labeled image data, complex blood vessel structure with different scales, and easy to be disturbed by the lesion area, is a concern for researchers. Thus, to address this problem, the study proposes a multiscale dense attention network for retinal blood vessel segmentation. First, based on U-Net architecture, the concurrent spatial and channel squeeze and channel excitation attention dense block (scSE-DB) is used to replace the traditional convolution layer, strengthening the feature propagation ability, and obtaining a dual calibration for feature information so that the model can better identify blood vessel pixels. Second, a cascade hole convolution module is embedded at the bottom of the network to capture multiscale vascular feature information and improve the network's ability to obtain deep semantic features. Finally, we performed the experiments on three datasets (DRIVE dataset, CHASE_DB1 dataset, and STARE dataset), and the results show that the accuracy of the proposed network is 96.50%, 96.62%, and 96.75%; the sensitivity is 84.17%, 83.34%, and 80.39%, and the specificity is 98.22%, 97.95%, and 98.67%, respectively. Generally, the results show that the segmentation performance of the proposed network outperforms that of other advanced algorithms.
Laser & Optoelectronics Progress
- Publication Date: Mar. 25, 2023
- Vol. 60, Issue 6, 0610011 (2023)
Reconstruction of Fan Beam X-Ray Fluorescence Computed Tomography Based on L1/2-Norm
Shuang Yang, Shanghai Jiang, Xinyu Hu, Binbin Luo, Mingfu Zhao, Bin Tang, Zourong Long, Shenghui Shi, Xue Zou, and Mi Zhou
As a molecular imaging mode, X-ray fluorescence computed tomography (XFCT) has the problems of long scanning times and large radiation doses. In general, the scanning time and radiation dose of XFCT are reduced by increasing the projection interval and reducing the number of projections. Therefore, to improve the quality of reconstructed images with few projections and iterations, an XFCT reconstruction algorithm based on the L1/2-norm is proposed. The numerical simulation results show that compared with the traditional Maximum Likelihood Expectation Maximization algorithm, the proposed XFCT reconstruction algorithm has a smaller root mean square error and a global image quality index closer to 1 with fewer projections and iterations, achieving the goal of improving the quality of reconstructed images with few projections and iterations. As a molecular imaging mode, X-ray fluorescence computed tomography (XFCT) has the problems of long scanning times and large radiation doses. In general, the scanning time and radiation dose of XFCT are reduced by increasing the projection interval and reducing the number of projections. Therefore, to improve the quality of reconstructed images with few projections and iterations, an XFCT reconstruction algorithm based on the L1/2-norm is proposed. The numerical simulation results show that compared with the traditional Maximum Likelihood Expectation Maximization algorithm, the proposed XFCT reconstruction algorithm has a smaller root mean square error and a global image quality index closer to 1 with fewer projections and iterations, achieving the goal of improving the quality of reconstructed images with few projections and iterations.
Laser & Optoelectronics Progress
- Publication Date: Mar. 25, 2023
- Vol. 60, Issue 6, 0610010 (2023)
Real-Time Detection of Small Targets Based on Lightweight YOLOv4
Yuqing Liu, Jiarong Sui, Xing Wei, Zhonglin Zhang, and Yan Zhou
A real-time detection algorithm F-YOLO for the feeding behavior of lightweight fish based on the fish swarm's texture, shape, and density characteristics is proposed to realize accurate feeding in fishery breeding based on the traditional detection algorithm. The initial backbone feature extraction network CSPDarkNet53 of the YOLOv4 algorithm is replaced by MobileNetV3, which significantly enhances the real-time detection performance of the network and the detection performance of small fish targets at the cost of a slight reduction in detection accuracy; channel pruning, and knowledge distillation are performed on the convolution layer of the network structure to compress the model and reduce the number of floating-point operations (FLOPs) and the amount of calculation; using optimized K-means clustering and DIoU loss function with global non-maximum suppression to determine the anchor frame, the problem of missing anchor frame caused by mutual occlusion of fish bodies are solved. The experimental results reveal that the model size of the suggested F-YOLO algorithm, the average recognition time of each image, the accuracy, the FLOPs, and detection speed in the embedded device are 13.7 MB, 50 ms, 99.13%, 1.64×1010, and 33 frame/s, respectively, which can provide theoretical guidance for the actual fishery breeding. A real-time detection algorithm F-YOLO for the feeding behavior of lightweight fish based on the fish swarm's texture, shape, and density characteristics is proposed to realize accurate feeding in fishery breeding based on the traditional detection algorithm. The initial backbone feature extraction network CSPDarkNet53 of the YOLOv4 algorithm is replaced by MobileNetV3, which significantly enhances the real-time detection performance of the network and the detection performance of small fish targets at the cost of a slight reduction in detection accuracy; channel pruning, and knowledge distillation are performed on the convolution layer of the network structure to compress the model and reduce the number of floating-point operations (FLOPs) and the amount of calculation; using optimized K-means clustering and DIoU loss function with global non-maximum suppression to determine the anchor frame, the problem of missing anchor frame caused by mutual occlusion of fish bodies are solved. The experimental results reveal that the model size of the suggested F-YOLO algorithm, the average recognition time of each image, the accuracy, the FLOPs, and detection speed in the embedded device are 13.7 MB, 50 ms, 99.13%, 1.64×1010, and 33 frame/s, respectively, which can provide theoretical guidance for the actual fishery breeding.
Laser & Optoelectronics Progress
- Publication Date: Mar. 25, 2023
- Vol. 60, Issue 6, 0610009 (2023)
Improved ResNet Image Classification Model Based on Tensor Synthesis Attention
Yunfei Qiu, Jiaxin Zhang, Hai Lan, and Jiaxu Zong
An improved ResNet-101 network model that fuses tensor synthesis attention (RTSA Net-101) is proposed to solve insufficient feature extraction and the indiscriminate contribution of the extracted features when processing image classification tasks using a convolutional neural network. First, the image features are extracted using a Resnet-101 backbone network and the tensor synthesis attention module is embedded after the convolution structure of the residual network. The features are calculated using a three-tensor product to obtain the attention feature matrix. Next, the Softmax function is used to normalize the attention feature matrix to assign weights to features and distinguish the contribution of features. Finally, the weighted sum of the weights and critical values are calculated as the final features in our proposed method to improve the image classification performance. Comparative experiments are conducted on natural image datasets, CIFAR-10 and CIFAR-100, and street brand dataset, SVHN. The classification accuracy values of the models are 96.12%, 81.60%, and 96.67%, respectively, and the average test running time of the images are 0.0258 s, 0.0260 s, and 0.0262 s, respectively. The experimental results show that compared with the other seven advanced image classification models, the RTSA Net-101 model can achieve higher classification accuracy and shorter test run time, and it can effectively enhance the feature learning ability of the network, thereby render the proposed model innovative and efficient. An improved ResNet-101 network model that fuses tensor synthesis attention (RTSA Net-101) is proposed to solve insufficient feature extraction and the indiscriminate contribution of the extracted features when processing image classification tasks using a convolutional neural network. First, the image features are extracted using a Resnet-101 backbone network and the tensor synthesis attention module is embedded after the convolution structure of the residual network. The features are calculated using a three-tensor product to obtain the attention feature matrix. Next, the Softmax function is used to normalize the attention feature matrix to assign weights to features and distinguish the contribution of features. Finally, the weighted sum of the weights and critical values are calculated as the final features in our proposed method to improve the image classification performance. Comparative experiments are conducted on natural image datasets, CIFAR-10 and CIFAR-100, and street brand dataset, SVHN. The classification accuracy values of the models are 96.12%, 81.60%, and 96.67%, respectively, and the average test running time of the images are 0.0258 s, 0.0260 s, and 0.0262 s, respectively. The experimental results show that compared with the other seven advanced image classification models, the RTSA Net-101 model can achieve higher classification accuracy and shorter test run time, and it can effectively enhance the feature learning ability of the network, thereby render the proposed model innovative and efficient.
Laser & Optoelectronics Progress
- Publication Date: Mar. 25, 2023
- Vol. 60, Issue 6, 0610008 (2023)
Fast Image Registration Method Based on Improved AKAZE Algorithm
Weidong Zhao, Junde Liu, Manman Wang, and Dan Li
A fast image matching method based on the improved accelerate-KAZE (AKAZE) algorithm is proposed to address the issues of low matching rate and weak robustness in UAV image matching. The proposed method first constructs the nonlinear scale space during the feature extraction stage using the AKAZE algorithm, and then efficiently describes the feature points using the fast retina keypoint (FREAK) descriptor. Later, the obtained feature points are prematched using the grid-based motion statistic (GMS) method to distinguish them with high robustness. The matching outcomes are then further screened using the basis of random sample consensus (RANSAC) algorithm. Experiments are conducted on an Oxford standard image dataset and an RSSCN7 remote sensing image dataset to verify the effectiveness of the proposed method. The proposed method is compared with the improved AKAZE, ORB, KAZE, and SIFT+FREAK algorithms. Continuous testing can guarantee that the proposed method can achieve fast image registration while maintaining high accuracy. It can maintain a high robustness under image illumination change, fuzzy transformation, and compression transformation and can meet the needs of UAV image real-time matching. A fast image matching method based on the improved accelerate-KAZE (AKAZE) algorithm is proposed to address the issues of low matching rate and weak robustness in UAV image matching. The proposed method first constructs the nonlinear scale space during the feature extraction stage using the AKAZE algorithm, and then efficiently describes the feature points using the fast retina keypoint (FREAK) descriptor. Later, the obtained feature points are prematched using the grid-based motion statistic (GMS) method to distinguish them with high robustness. The matching outcomes are then further screened using the basis of random sample consensus (RANSAC) algorithm. Experiments are conducted on an Oxford standard image dataset and an RSSCN7 remote sensing image dataset to verify the effectiveness of the proposed method. The proposed method is compared with the improved AKAZE, ORB, KAZE, and SIFT+FREAK algorithms. Continuous testing can guarantee that the proposed method can achieve fast image registration while maintaining high accuracy. It can maintain a high robustness under image illumination change, fuzzy transformation, and compression transformation and can meet the needs of UAV image real-time matching.
Laser & Optoelectronics Progress
- Publication Date: Mar. 25, 2023
- Vol. 60, Issue 6, 0610007 (2023)
Topics
© Copyright 2018-2021 | Chinese Laser Press. All Rights Reserved 沪ICP备15018463号-20